Legal AI Agent
Zero to Hero: Converting a RAG Legal Chatbot to Google ADK
Introduction
Welcome to the LegalAI tutorial! This project create an AI European law compliance application using Google Agent Development Kit (ADK) pipeline.
Rather than using classic vector search embeddings sequentially (like LangChain's Chroma), this application embraces the ADK ParallelAgent model. When you ask if your technology is compliant, the system concurrently sends an act_retriever_agent directly into the EU AI Act dataset, AND a regulatory_analyst_agent evaluating overlapping laws like GDPR or Copyright. A final Lead Compliance Officer synthesizes these two dimensions.
Project Structure
We split our application up into elegant, manageable pieces. Here is what the folder structure looks like:
/legalai/
├── __init__.py # 🚪 Required package declaration
├── agent.py # 🧠 The Logic: Parallel Research + Sequential Compliance
├── tools.py # 🛠️ The Hooks: Fetch articles & secondary impacts
├── prompts.py # 🎭 The Instructions: Roles defined
├── standalone_legalai.py # ⚙️ Testing script (Complete run via CLI)
├── .env # 🔑 Keys pointing to Gemini 2.5 Flash
└── run_agent.sh # 🚀 Testing launcher
Step 2: Vector Mock Tools
Our retriever agents need context. We define tools simulating specific queries:
# tools.py
def query_eu_ai_act(query: str) -> dict:
# Represents the primary document query
context_data = [
"Article 5: Prohibited AI Practices (Unacceptable Risk) - This includes biometric categorisation systems that use sensitive characteristics, untargeted scraping of facial images, and AI systems that manipulate human behaviour.",
"Article 6: High-Risk AI Systems - AI used in critical infrastructure, education, employment, and law enforcement are high-risk."
]
results = [doc for doc in context_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific clause found for that query in the EU AI Act database."]
return {"status": "success", "retrieved_articles": results}
def get_general_eu_legal_impact(query: str) -> dict:
# Represents secondary directive queries
secondary_data = [
"GDPR Overlap: If the AI system processes personal data, Article 22 of the GDPR continues to apply fully alongside the AI act.",
"Copyright Directive: General Purpose AI providers must respect Union law on copyright and related rights."
]
results = [doc for doc in secondary_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific secondary legal impacts found."]
return {"status": "success", "secondary_analysis": results}
Step 3: State Injection and Personas
The Lead Compliance Officer analyzes the reports handed up by the parallel specialists. Using ADK's prompt templating, we inject the {ai_act_context} and {regulatory_analysis} explicitly into the Persona context window.
# prompts.py
LEAD_COMPLIANCE_OFFICER_PROMPT = """
You are the Lead EU AI Compliance Officer, serving as a chatbot to help users navigate the complicated paths of AI regulations inside the EU.
You have received detailed reports from your specialized agents:
1. **AI Act Retriever**: Gives you specific clauses and risk categorizations direct from the Act.
2. **Regulatory Analyst**: Gives you supplementary context on data governance, GDPR overlaps, etc.
Task: Synthesize this information into a smart, simple-to-understand, and professional briefing for the user.
---
### AI ACT CLAUSES RETRIEVED
{ai_act_context}
---
### SECONDARY REGULATORY ANALYSIS
{regulatory_analysis}
---
Now, please provide a comprehensive legal evaluation to the user. Always state that this is AI-generated advice.
"""
{ai_act_context} is populated seamlessly because we assign it to the output of our act retriever agent. The ADK state machine drops it perfectly into the curly braces!
Step 4: The Parallel Pipeline
A nested ParallelAgent speeds up Operations massively over sequential run loops by doing tasks concurrently.
# agent.py
from google.adk.agents import LlmAgent, ParallelAgent, SequentialAgent
from .tools import query_eu_ai_act, get_general_eu_legal_impact
from .prompts import ACT_RETRIEVER_PROMPT, REGULATORY_ANALYST_PROMPT, LEAD_COMPLIANCE_OFFICER_PROMPT
act_retriever_agent = LlmAgent(
name="act_retriever_agent",
model="gemini-2.5-flash",
instruction=ACT_RETRIEVER_PROMPT,
tools=[query_eu_ai_act],
output_key="ai_act_context"
)
regulatory_analyst_agent = LlmAgent(
name="regulatory_analyst_agent",
model="gemini-2.5-flash",
instruction=REGULATORY_ANALYST_PROMPT,
tools=[get_general_eu_legal_impact],
output_key="regulatory_analysis"
)
research_team = ParallelAgent(
name="research_team",
sub_agents=[act_retriever_agent, regulatory_analyst_agent]
)
lead_compliance_officer = LlmAgent(
name="lead_compliance_officer",
model="gemini-2.5-flash",
instruction=LEAD_COMPLIANCE_OFFICER_PROMPT,
output_key="final_compliance_report"
)
root_agent = SequentialAgent(
name="legalai_agent",
sub_agents=[research_team, lead_compliance_officer]
)
Step 5: The Complete Script
To bypass the need for modular directory architecture and run this app instantly from the CLI, here is the entirely self-contained logic packaged into one script.
import os
import asyncio
from dotenv import load_dotenv
from google.adk.agents import LlmAgent, ParallelAgent, SequentialAgent
# Load Environment Variables
load_dotenv(dotenv_path=os.path.join(os.path.dirname(os.path.abspath(__file__)), ".env"))
# --- TOOLS ---
def query_eu_ai_act(query: str) -> dict:
context_data = [
"Article 5: Prohibited AI Practices (Unacceptable Risk) - This includes biometric categorisation systems that use sensitive characteristics, untargeted scraping of facial images...",
"Article 6: High-Risk AI Systems - AI used in critical infrastructure..."
]
results = [doc for doc in context_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific clause found for that query in the EU AI Act database."]
return {"status": "success", "retrieved_articles": results}
def get_general_eu_legal_impact(query: str) -> dict:
secondary_data = [
"GDPR Overlap: If the AI system processes personal data, Article 22 of the GDPR continues to apply fully alongside the AI act.",
"Copyright Directive: General Purpose AI providers must respect Union law on copyright and related rights."
]
results = [doc for doc in secondary_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific secondary legal impacts found."]
return {"status": "success", "secondary_analysis": results}
# --- AGENTS ---
act_retriever_agent = LlmAgent(
name="act_retriever_agent",
model="gemini-2.5-flash",
instruction="Extract specific clauses from the EU AI Act directly based on the query.",
tools=[query_eu_ai_act],
output_key="ai_act_context"
)
regulatory_analyst_agent = LlmAgent(
name="regulatory_analyst_agent",
model="gemini-2.5-flash",
instruction="Extract broader European law implications (e.g., GDPR, copyright) related to the query.",
tools=[get_general_eu_legal_impact],
output_key="regulatory_analysis"
)
memory_team = ParallelAgent(
name="research_team",
sub_agents=[act_retriever_agent, regulatory_analyst_agent]
)
lead_compliance_officer = LlmAgent(
name="lead_compliance_officer",
model="gemini-2.5-flash",
instruction="Synthesize the findings from your act_retriever and regulatory_analyst sub-agents into an easy-to-read compliance report. Warn the user it's AI generated.",
output_key="final_compliance_report"
)
root_agent = SequentialAgent(
name="legalai_agent",
sub_agents=[memory_team, lead_compliance_officer]
)
if __name__ == "__main__":
from google.adk.cli.cli import run_cli
run_cli(agent_parent_dir=os.path.dirname(os.path.dirname(os.path.abspath(__file__))), agent_folder_name="legalai")
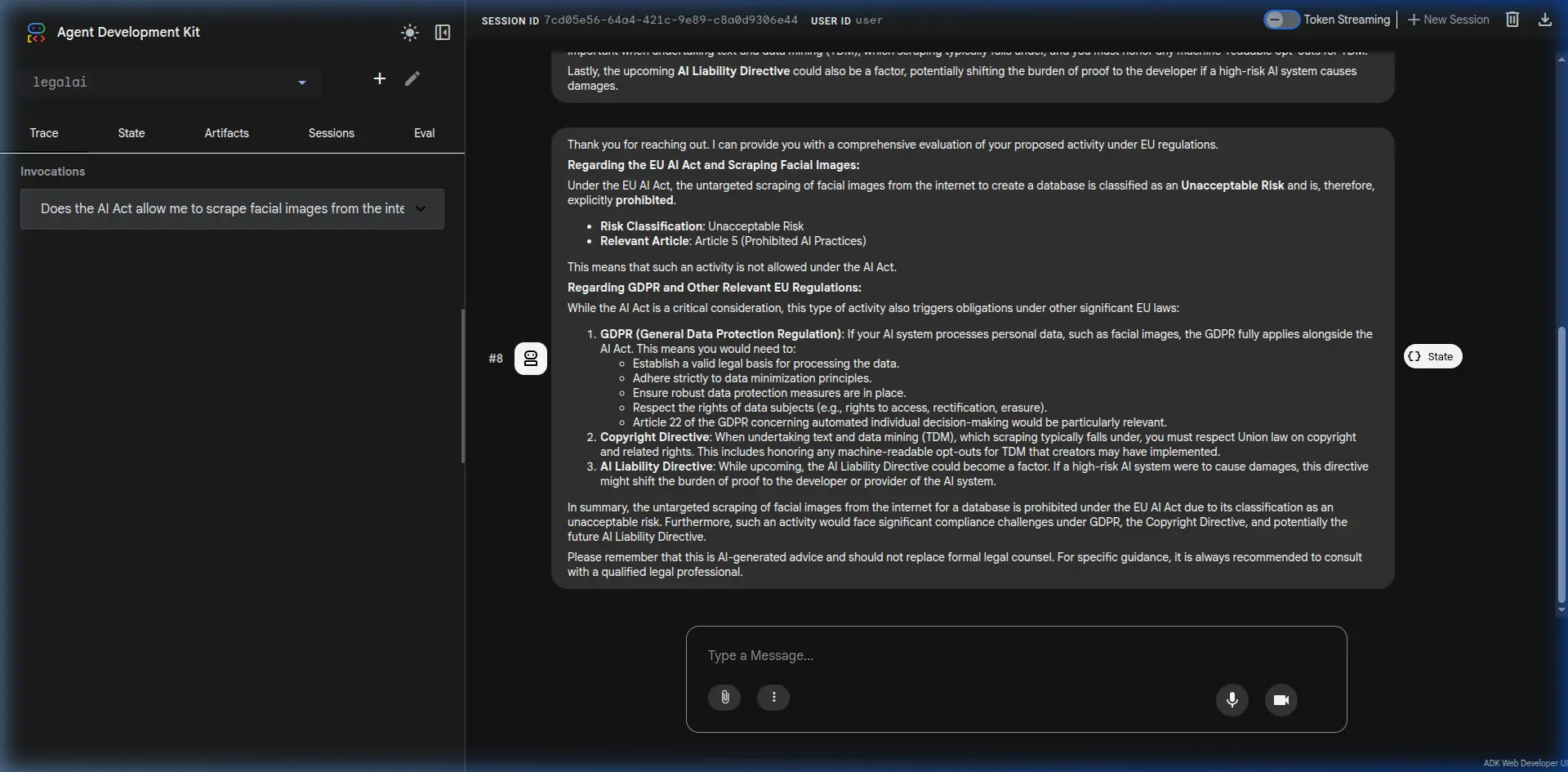
Final Result
Below is a screenshot demonstrating the LegalAI agent in action. It concurrently searches the AI Act database and the secondary Europe liability regulations, synthesizing them into a coherent legal evaluation!