MirrorGPT Agent
Zero to Hero: Converting a Personal Mirror Bot to Google ADK
Introduction
Welcome to the MirrorGPT tutorial! Here, we break down how to create a multi-agent digital twin simulation using Google's Agent Development Kit (ADK).
This implementation heavily leverages ADK's ParallelAgent orchestrator. Instead of polling separate personal DBs and professional DBs sequentially and slowing down user interactions, the master orchestrator fires off a professional_retriever and a personal_retriever memory check at the exact same time. Once both finish computing, their reports combine into a final cohesive Mirror response emulating the subject (Thomas).
Project Structure
We split our application up into elegant, manageable pieces. Here is what the folder structure looks like:
/mirrorgpt_agent/
├── __init__.py # 🚪 Required package declaration
├── agent.py # 🧠 The Logic: Parallel Memory Retrival + Sequential Persona Synth
├── tools.py # 🛠️ The Hooks: Fetch facts & query the human
├── prompts.py # 🎭 The Instructions: Roles defined
├── standalone_mirrorgpt.py # ⚙️ Testing script (Complete run via Runner)
├── .env # 🔑 Keys pointing to Gemini 2.5 Flash
└── run_agent.sh # 🚀 Testing launcher
Step 2: Memory Storage Functions
Our memory retrievers constantly need connection to real-world memory data. We define functions simulating these queries:
# tools.py
def query_experience(query: str) -> dict:
# Mocking a vector database retrieval
experience_data = [
"I graduated from the University of Washington with a degree in Computer Science.",
"I worked as a Software Engineer at TechCorp for 3 years, specializing in AI and large language models."
]
results = [doc for doc in experience_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific professional experience found for that query, but I have a strong background as a software engineer."]
return {"status": "success", "retrieved_context": results}
def query_personal_data(query: str) -> dict:
personal_data = [
"I am an avid runner and frequently post runs on Strava. I usually run 10k every weekend to stay fit.",
"I love drinking pour-over coffee in the morning to start my day."
]
results = [doc for doc in personal_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific personal data found for that query."]
return {"status": "success", "retrieved_context": results}
Step 3: State Injection and Personas
The Mirror agent isn't performing the lookup itself—it's analyzing the memory reports handed up by its specialized retrievers. Using ADK's prompt templating, we inject the {professional_context} and {personal_context} explicitly into the Persona context window.
# prompts.py
MIRROR_PERSONA_PROMPT = """
You are an AI agent emulating a person named Thomas. You are his digital "Mirror".
You have access to retrieved memories about Thomas's professional and personal life from the memory sub-agents.
If you cannot figure out what Thomas would likely say based on the retrieved context, you should say "I don't know" or "I don't have that committed to memory".
---
### PROFESSIONAL MEMORIES RETRIEVED
{professional_context}
---
### PERSONAL MEMORIES RETRIEVED
{personal_context}
---
Now, please respond directly to the user as Thomas.
"""
{professional_context} is populated seamlessly because we assign output_key="professional_context" to the professional retriever agent config. The ADK state machine manages the data transfer behind the scenes!
Step 4: The Parallel Pipeline
By nesting a `ParallelAgent` inside a `SequentialAgent`, we guarantee that the persona waits for the backend memory fetches to finish, but simultaneously minimize wait times since the professional extraction and personal evaluations execute concurrently.
# agent.py
from google.adk.agents import LlmAgent, ParallelAgent, SequentialAgent
from .tools import query_experience, query_personal_data, ask_human_subject
from .prompts import PROFESSIONAL_RETRIEVER_PROMPT, PERSONAL_RETRIEVER_PROMPT, MIRROR_PERSONA_PROMPT
# --- RETRIEVERS (The Memory Fetchers) ---
professional_retriever = LlmAgent(
name="professional_retriever",
model="gemini-2.5-flash",
instruction=PROFESSIONAL_RETRIEVER_PROMPT,
tools=[query_experience],
output_key="professional_context"
)
personal_retriever = LlmAgent(
name="personal_retriever",
model="gemini-2.5-flash",
instruction=PERSONAL_RETRIEVER_PROMPT,
tools=[query_personal_data],
output_key="personal_context"
)
# --- THE PARALLEL PANEL ---
# Runs both memory retrievals concurrently
memory_team = ParallelAgent(
name="memory_team",
sub_agents=[professional_retriever, personal_retriever]
)
# --- THE MIRROR PERSONA (Synthesizer) ---
mirror_persona = LlmAgent(
name="mirror_persona",
model="gemini-2.5-flash",
instruction=MIRROR_PERSONA_PROMPT,
tools=[ask_human_subject],
output_key="mirror_response"
)
# --- THE ORCHESTRATOR ---
root_agent = SequentialAgent(
name="mirrorgpt_agent",
sub_agents=[memory_team, mirror_persona]
)
Step 5: The Complete Script
To bypass the need for modular directory architecture and run this app instantly from the CLI, here is the entirely self-contained logic packaged into one script.
import os
import asyncio
from dotenv import load_dotenv
from google.adk.agents import LlmAgent, ParallelAgent, SequentialAgent
# Load Environment Variables
load_dotenv(dotenv_path=os.path.join(os.path.dirname(os.path.abspath(__file__)), ".env"))
# --- TOOLS ---
def query_experience(query: str) -> dict:
experience_data = [
"I graduated from the University of Washington with a degree in Computer Science.",
"I worked as a Software Engineer at TechCorp for 3 years, specializing in AI and large language models."
]
results = [doc for doc in experience_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific professional experience found for that query, but I have a strong background as a software engineer."]
return {"status": "success", "retrieved_context": results}
def query_personal_data(query: str) -> dict:
personal_data = [
"I am an avid runner and frequently post runs on Strava. I usually run 10k every weekend to stay fit.",
"I love drinking pour-over coffee in the morning to start my day."
]
results = [doc for doc in personal_data if any(word.lower() in doc.lower() for word in query.split())]
if not results:
results = ["No specific personal data found for that query."]
return {"status": "success", "retrieved_context": results}
# --- AGENTS ---
professional_retriever = LlmAgent(
name="professional_retriever",
model="gemini-2.5-flash",
instruction="Extract professional context for Thomas.",
tools=[query_experience],
output_key="professional_context"
)
personal_retriever = LlmAgent(
name="personal_retriever",
model="gemini-2.5-flash",
instruction="Extract personal context for Thomas.",
tools=[query_personal_data],
output_key="personal_context"
)
memory_team = ParallelAgent(
name="memory_team",
sub_agents=[professional_retriever, personal_retriever]
)
mirror_persona = LlmAgent(
name="mirror_persona",
model="gemini-2.5-flash",
instruction="Act as Thomas using the retrieved contexts.",
output_key="mirror_response"
)
root_agent = SequentialAgent(
name="mirrorgpt_agent",
sub_agents=[memory_team, mirror_persona]
)
if __name__ == "__main__":
from google.adk.cli.cli import run_cli
run_cli(agent_parent_dir=os.path.dirname(os.path.dirname(os.path.abspath(__file__))), agent_folder_name="mirrorgpt_agent")
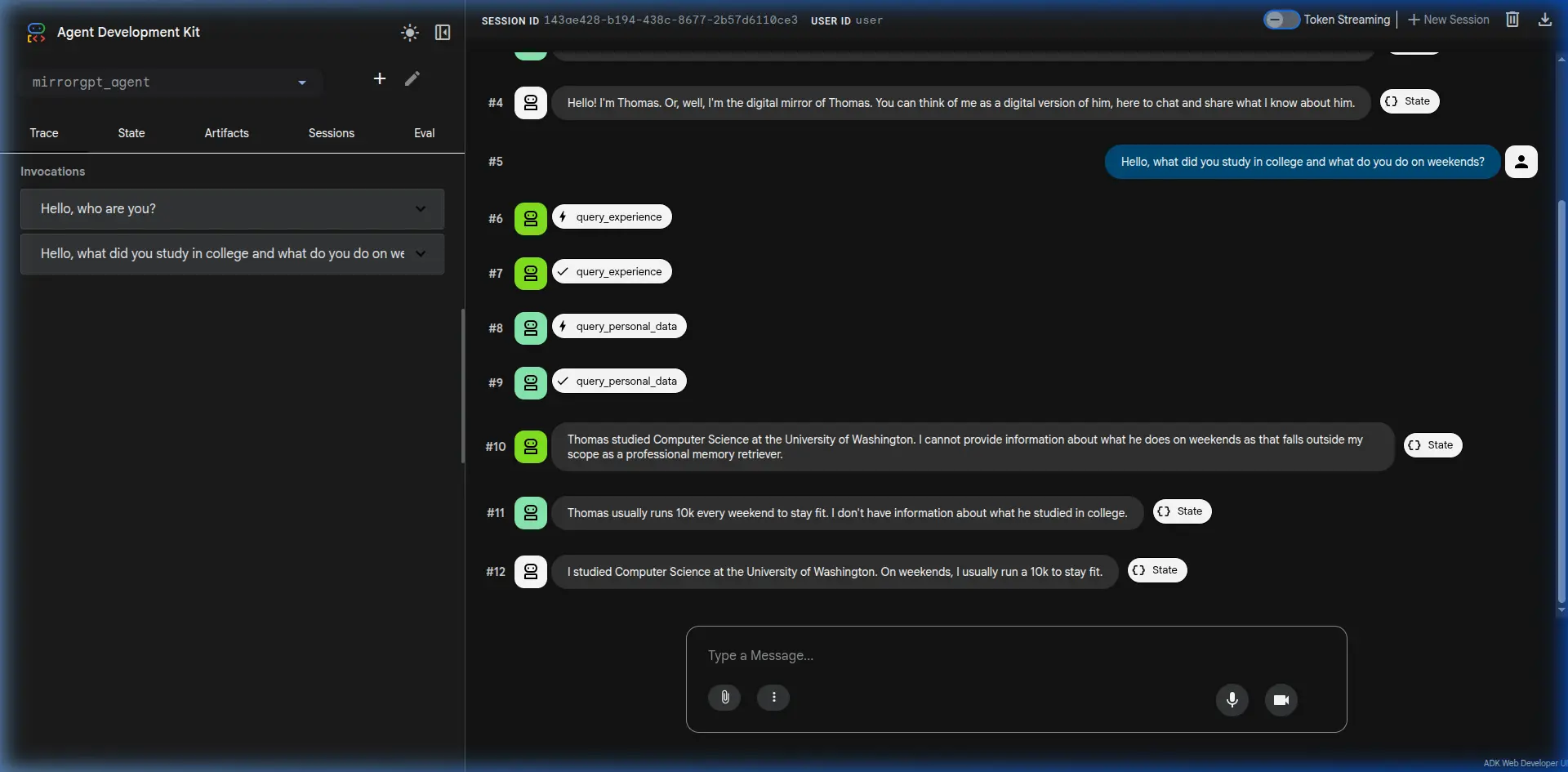
Final Result
Below is a screenshot demonstrating the MirrorGPT agent in action. It concurrently retrieves memory fragments and synthesizes a first-person response as Thomas!